https://nju-projectn.github.io/ics-pa-gitbook/ics2025/PA1.html
Note
1.2 开天辟地的篇章
Turing Machine
一个最简单的真实计算机(图灵机,Turing Machine,TRM)需要满足的条件:
- 结构上,TRM 有存储器、寄存器、加法器;
- 工作方式上,TRM 不断重复以下过程:从 PC 指示的存储器位置取出指令,执行指令,更新 PC。
我们可以把计算机看成一个状态机。在状态机模型里面,指令可以看成是计算机进行一次状态转移的输入激励。
1.3 RTFSC
Makefile 中的 $< $@
$(OBJ_DIR)/%.o: %.c
@echo + CC $<
@mkdir -p $(dir $@)
@$(CC) $(CFLAGS) -c -o $@ $<
$(call call_fixdep, $(@:.o=.d), $@)$< 是自动化变量,代表第一个依赖文件的名称(.c 文件) 。$@ 是自动化变量,代表当前规则中的目标文件的全路径(.o 文件)。
1.4 基础设施
strtok() 函数
char *strtok(char *_Nullable restrict str, const char *restrict delim);strtok() 函数用于将一个字符串分裂成多段。
str 在第一次调用时被传入,之后调用只需传入 NULL。使用 strtok() 函数会改变原始的字符串,因此可能需要 strcpy() 。
返回值为 buffer 被 delim 分割得到的第一个片段,调用之后将会更新 buffer 为剩下的部分;如果没有可以返回的片段则返回 NULL。
delim 可以传入多个分隔符,但和 split 函数不同,会分别以不同的分隔符进行分割,且连续的分隔符会被当成一个处理。
#include <string.h>
#include <stdio.h>
int main() {
char str[] = "1;;;2 3";
char *token = strtok(str, " ;");
printf("%s\n", token);
// Output: 1
token = strtok(NULL, " ;");
printf("%s\n", token);
// Output: 2
token = strtok(NULL, " ;");
printf("%s\n", token);
// Output: 3
return 0;
}sscanf() 函数
和 scanf() 差不多吧,不过第一个参数变成了要进行格式化读取的源字符串。
1.5 表达式求值
Backus-Naur Form (BNF)
BNF 描述了符号是如何组合成句法上合法的语句的。
每个 BNF 由三个核心部分组成:一些非终结符、一些终结符及一系列派生规则。
终结符是语言中最基本的、不可再分的符号,是推导过程的终点,不能再通过语法规则被替换为其他符号,比如具体的字面量值、运算符、关键字等。
非终结符是表示语法结构或范畴的抽象符号,不是最终文本的一部分,而是用来定义如何组合终结符和其他非终结符,比如一个<表达式>、<语句>或<变量声明>。
一条派生规则在 BNF 里被写作 <symbol> ::= __expression__,其中:
<symbol>是一个非终结符;::=是替换为的意思;__expression__是被替换的语句,可以由一条或多条语句组成,如果有多个选择,使用|连接两条语句。
用 BNF 语法来描述自身:
<syntax> ::= <rule> | <rule> <syntax>
<rule> ::= <opt-whitespace> "<" <rule-name> ">" <opt-whitespace> "::=" <opt-whitespace> <expression> <line-end>
<opt-whitespace> ::= " " <opt-whitespace> | ""
<expression> ::= <list> | <list> <opt-whitespace> "|" <opt-whitespace> <expression>
<line-end> ::= <opt-whitespace> <EOL> | <line-end> <line-end>
<list> ::= <term> | <term> <opt-whitespace> <list>
<term> ::= <literal> | "<" <rule-name> ">"
<literal> ::= '"' <text1> '"' | "'" <text2> "'"
<text1> ::= "" | <character1> <text1>
<text2> ::= "" | <character2> <text2>
<character> ::= <letter> | <digit> | <symbol>
<letter> ::= "A" | "B" | "C" | "D" | "E" | "F" | "G" | "H" | "I" | "J" | "K" | "L" | "M" | "N" | "O" | "P" | "Q" | "R" | "S" | "T" | "U" | "V" | "W" | "X" | "Y" | "Z" | "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z"
<digit> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
<symbol> ::= "|" | " " | "!" | "#" | "$" | "%" | "&" | "(" | ")" | "*" | "+" | "," | "-" | "." | "/" | ":" | ";" | ">" | "=" | "<" | "?" | "@" | "[" | "\" | "]" | "^" | "_" | "`" | "{" | "}" | "~"
<character1> ::= <character> | "'"
<character2> ::= <character> | '"'
<rule-name> ::= <letter> | <rule-name> <rule-char>
<rule-char> ::= <letter> | <digit> | "-"1.6 监视点
- Fault: 实现错误的代码,例如
if (p = NULL)- Error: 程序执行时不符合预期的状态,例如
p被错误地赋值成NULL- Failure: 能直接观测到的错误,例如程序触发了段错误
调试其实就是从观测到的 Failure 一步一步回溯寻找 Fault 的过程。找到了 Fault 之后,我们就很快知道应该如何修改错误的代码了。但从上面的例子也可以看出, 调试之所以不容易, 恰恰是因为:
- Fault 不一定马上触发 Error
- 触发了 Error 也不一定马上转变成可观测的 Failure
- Error会像滚雪球一般越积越多, 当我们观测到 Failure 的时候, 其实已经距离 Fault 非常遥远了
理解了这些原因之后,我们就可以指定相应的策略了:
- 尽可能将 Fault 转变为 Error。这其实就是测试做的事情。
- 尽早观测到 Error 的存在。观测到 Error 的时机直接决定了调试的难度:如果等到触发 Failure 的时候才发现 Error 的存在,调试就会比较困难;但如果能在 Error 刚刚触发的时候就观测到它,调试难度也就大大降低了。
-Wall-Werror在编译时期将潜在的 Fault 直接转变成 Failure。assert()在运行时刻将 Error 直接转变为 Failure。printf()通过输出的方式观察潜在的 Error。- GDB
Writeup
1.2 开天辟地的篇章
Q.1 计算机可以没有寄存器吗? (建议二周目思考)
如果没有寄存器, 计算机还可以工作吗? 如果可以, 这会对硬件提供的编程模型有什么影响呢?
就算你是二周目来思考这个问题, 你也有可能是第一次听到”编程模型”这个概念. 不过如果一周目的时候你已经仔细地阅读过ISA手册, 你会记得确实有这么个概念. 所以, 如果想知道什么是编程模型, RTFM吧.
Prompt: 什么是硬件提供的编程模型
一个完整的硬件编程模型通常包含以下几个维度:
#### **指令集架构 (Instruction Set Architecture, ISA)**
这是编程模型最核心的部分。它规定了硬件能听懂的所有“指令”。
- **指令类型:** 算术运算(加减乘除)、逻辑运算、数据传输(装载、存储)、流程控制(跳转、分支)。
- **指令格式:** 每一条机器码是多少位,操作码(Opcode)在哪,操作数(Operand)在哪。
- **常见的 ISA:** x86 (Intel/AMD), ARM (手机/Mac), RISC-V (开源架构)。
#### **寄存器组织 (Registers)**
硬件会暴露出一组有限的、速度极快的存储单元供软件直接操作。
- **通用寄存器:** 用来存放中间计算结果(如 x86 的 `RAX`, `RBX`)。
- **特殊功能寄存器:** 比如程序计数器(PC/IP)指向下一条执行的指令,栈指针(SP)管理函数调用。
- **状态寄存器:** 记录上一条指令是否产生了溢出、是否为零或负数。
#### **内存模型 (Memory Model)**
规定了程序如何访问内存。
- **寻址空间:** 硬件支持多大的地址范围(如 32 位支持 4GB,64 位支持更大)。
- **内存对齐:** 某些硬件要求读取的数据必须在特定的地址边界上(比如 4 字节的整数必须从 4 的倍数地址开始读)。
- **内存一致性:** 在多核 CPU 环境下,当一个核心修改了内存,其他核心什么时候能“看到”这个修改。
#### **执行模式与特权级**
硬件定义了程序运行的“权限”。
- **用户态 vs 内核态:** 比如普通应用程序不能直接操作硬盘或关闭中断,只有操作系统内核才有这些特权。
- **中断处理:** 当硬件设备(如键盘、网卡)有数据进来时,硬件如何强制暂停当前的程序并转去执行特定的“中断处理程序”。
计算机可以没有寄存器,可以将数据全部存储在内存中。但是会导致:
- 计算机性能下降
寄存器的访问速度比内存快约 100 倍,没有寄存器后将从内存中读取全部数据(甚至是 PC),导致性能瓶颈。 - 指令集变得臃肿
将原来寄存器名称用内存地址替代,导致指令长度暴增。
Q.2 尝试理解计算机如何计算
在看到上述例子之前, 你可能会觉得指令是一个既神秘又难以理解的概念. 不过当你看到对应的C代码时, 你就会发现指令做的事情竟然这么简单! 而且看上去还有点蠢, 你随手写一个for循环都要比这段C代码看上去更高级.
不过你也不妨站在计算机的角度来理解一下, 计算机究竟是怎么通过这种既简单又笨拙的方式来计算
1+2+...+100的. 这种理解会使你建立”程序如何在计算机上运行”的最初原的认识.
略
Q.3 从状态机视角理解程序运行
以上一小节中
1+2+...+100的指令序列为例, 尝试画出这个程序的状态机.这个程序比较简单, 需要更新的状态只包括
PC和r1,r2这两个寄存器, 因此我们用一个三元组(PC, r1, r2)就可以表示程序的所有状态, 而无需画出内存的具体状态. 初始状态是(0, x, x), 此处的x表示未初始化. 程序PC=0处的指令是mov r1, 0, 执行完之后PC会指向下一条指令, 因此下一个状态是(1, 0, x). 如此类推, 我们可以画出执行前3条指令的状态转移过程:(0, x, x) -> (1, 0, x) -> (2, 0, 0) -> (3, 0, 1)请你尝试继续画出这个状态机, 其中程序中的循环只需要画出前两次循环和最后两次循环即可.
(0, x, x) -> (1, 0, x)
-> (2, 0, 0) -> (3, 0, 1) -> (4, 1, 1) // 第 1 次循环
-> (2, 1, 1) -> (3, 1, 2) -> (4, 3, 2) // 第 2 次循环
-> ...
-> (2, 4851, 98) -> (3, 4851, 99) -> (4, 4950, 99) // 第 99 次循环
-> (2, 4950, 99) -> (3, 4950, 100) -> (4, 5050, 100) // 第 100 次循环
-> (5, 5050, 100) -> (5, 5050, 100), ...1.3 RTFSC
Q.1 kconfig生成的宏与条件编译
我们已经在上文提到过, kconfig会根据配置选项的结果在
nemu/include/generated/autoconf.h中定义一些形如CONFIG_xxx的宏, 我们可以在C代码中通过条件编译的功能对这些宏进行测试, 来判断是否编译某些代码. 例如, 当CONFIG_DEVICE这个宏没有定义时, 设备相关的代码就无需进行编译.为了编写更紧凑的代码, 我们在
nemu/include/macro.h中定义了一些专门用来对宏进行测试的宏. 例如IFDEF(CONFIG_DEVICE, init_device());表示, 如果定义了CONFIG_DEVICE, 才会调用init_device()函数; 而MUXDEF(CONFIG_TRACE, "ON", "OFF")则表示, 如果定义了CONFIG_TRACE, 则预处理结果为"ON"("OFF"在预处理后会消失), 否则预处理结果为"OFF".这些宏的功能非常神奇, 你知道这些宏是如何工作的吗?
// macro concatenation
#define concat_temp(x, y) x ## y
#define concat(x, y) concat_temp(x, y)
// --sniffed--
// macro testing
// See https://stackoverflow.com/questions/26099745/test-if-preprocessor-symbol-is-defined-inside-macro
#define CHOOSE2nd(a, b, ...) b
#define MUX_WITH_COMMA(contain_comma, a, b) CHOOSE2nd(contain_comma a, b)
#define MUX_MACRO_PROPERTY(p, macro, a, b) MUX_WITH_COMMA(concat(p, macro), a, b)
// define placeholders for some property
#define __P_DEF_0 X,
#define __P_DEF_1 X,
#define __P_ONE_1 X,
#define __P_ZERO_0 X,
// define some selection functions based on the properties of BOOLEAN macro
#define MUXDEF(macro, X, Y) MUX_MACRO_PROPERTY(__P_DEF_, macro, X, Y)
// --sniffed--
// simplification for conditional compilation
#define __IGNORE(...)
#define __KEEP(...) __VA_ARGS__
// keep the code if a boolean macro is defined
#define IFDEF(macro, ...) MUXDEF(macro, __KEEP, __IGNORE)(__VA_ARGS__)在 nemu/include/macro.h 中定义了一些宏,可以看到 IFDEF 宏是 MUXDEF 宏的一种特例。
MUXDEF 宏接受三个参数:macro, X, Y,并调用 MUX_MACRO_PROPERTY(__P_DEF_, macro, X, Y)。
MUX_MACRO_PROPERTY(p, macro, a, b) 宏将调用 MUX_WITH_COMMA(contain_comma, a, b) 宏,其中 contain_comma 参数由 p 和 macro 拼接得到,即得到 __P_DEF_$macro。
而生成的 nemu/include/generated/autoconf.h 中对 boolean 类型生成的宏是 0/1 格式的,如果宏 macro 定义了,会得到 __P_DEF_0 或 __P_DEF_1(检查是否定义时,我们不关心它的值,所以 __P_DEF_0 和 __P_DEF_1 的值是一样的,都是 X, )。如果宏没有定义,则会原样得到 __P_DEF_$macro 。
传入 MUX_WITH_COMMA 后,如果是 macro 定义的值是 0 或 1,则 CHOOSE2nd(X, X, Y),即返回 X,否则 CHOOSE(__P_DEF_$macro X, Y),返回 Y,由此可以实现在预编译阶段进行条件编译。
其他的宏原理也类似,不再叙述。
其他的一些细节:
#define concat_temp(x, y) x ## y
#define concat(x, y) concat_temp(x, y)- 为什么要两层? 在 C 语言中,如果直接使用
##,宏参数如果是另一个宏,它不会被展开。通过增加一层concat_temp,可以强制预处理器先展开x和y的内容,再进行物理连接。
Q.2 为什么全部都是函数?
阅读
init_monitor()函数的代码, 你会发现里面全部都是函数调用. 按道理, 把相应的函数体在init_monitor()中展开也不影响代码的正确性. 相比之下, 在这里使用函数有什么好处呢?
解耦。
Q.3 参数的处理过程
另外的一个问题是, 这些参数是从哪里来的呢?
一般来说,参数在执行命令时从终端传入,然后由终端调用操作系统调用执行程序,并将拆分好的参数字符串数组传递给操作系统。操作系统将这些字符串复制到新创建的进程的用户栈中,并在栈上初始化 argc 和 argv 的值。
启动程序时,操作系统将控制权交给程序的入口点(通常是一个叫 _start 的函数,由 C 运行时库 CRT 提供)。_start 函数将命令行参数打包,调用 main(argc, argv)。
在本例中参数进一步从 main 传递到 init_monitor 中。
Q.4 谁来指示程序的结束?
在程序设计课上老师告诉你, 当程序执行到
main()函数返回处的时候, 程序就退出了, 你对此深信不疑. 但你是否怀疑过, 凭什么程序执行到main()函数的返回处就结束了? 如果有人告诉你, 程序设计课上老师的说法是错的, 你有办法来证明/反驳吗? 如果你对此感兴趣, 请在互联网上搜索相关内容.
stdlib.h 中提供了 atexit 函数,使得我们能够在程序“退出”时运行一些函数。这就说明 main 函数返回时并不代表程序的结束。
实际上,在 _start 调用完 main 函数后,会调用 exit 函数来执行一些退出程序前的操作,使用 atexit 注册的函数就在此时被调用,在最后会调用操作系统提供的系统调用来切换上下文至系统,至此程序正式退出。
Q.5 有始有终 (建议二周目思考)
对于GNU/Linux上的一个程序, 怎么样才算开始? 怎么样才算是结束? 对于在NEMU中运行的程序, 问题的答案又是什么呢?
与此相关的问题还有: NEMU中为什么要有
nemu_trap? 为什么要有monitor?
结合 Q.3 和 Q.4,一个程序的生命周期从操作系统调用(GNU/Linux 上的 execve)被调用,程序得到上下文开始,到执行的程序调用操作系统调用(GNU/Linux 上的 _exit)退出程序,将上下文交还系统为止。
由于 NEMU 是一个 Bare-metal 模拟器,在 NEMU 主循环(cpu_exec)执行后(也就是实机上电的操作),被加载到内存中的程序就开始运行。但是 CPU 一旦通电,除非断电,否则无法停止 TRM 循环。所以需要一个自定义的特殊指令 nemu_trap 来指示停机,将控制权交还外层模拟器。
monitor 的作用是控制程序的生命周期,并且提供了一些调试的接口。相当于实机中的 Bootloader(BIOS/UEFI) + Debugger 。
Q.6 为NEMU编译时添加GDB调试信息
menuconfig已经为大家准备好相应选项了, 你只需要打开它:
Build Options [*] Enable debug information然后清除编译结果并重新编译即可. 尝试阅读相关代码, 理解开启上述menuconfig选项后会导致编译NEMU时的选项产生什么变化.
我们知道 menuconfig 的配置文件是 Kconfig 文件,在该文件中我们可以找到如下配置:
config CC_DEBUG
bool "Enable debug information"
default n说明 CC_DEBUG 开关控制着编译时调试信息的选项,我们知道编译时的选项应该与 Makefile 配置有关,所以我们可以在 Makefile 中找到:
CFLAGS_BUILD += $(if $(CONFIG_CC_DEBUG),-Og -ggdb3,)该行代码在 CC_DEBUG 开启时往编译参数中添加了 -Og -ggdb3 两个参数。查询可知:
-Og代表调试级别的优化,是-O0和-O2为调试目的的折中方案,启用了一些不干扰调试的选项;-ggdb3中的g代表生成调试信息(符号表),能够将二进制信息映射回源代码,方便调试;gdb代表调试信息为 GDB 调试器优化;3代表调试信息的级别(最高级别,包含宏定义)。
Q.7 优美地退出
为了测试大家是否已经理解框架代码, 我们给大家设置一个练习: 如果在运行NEMU之后直接键入
q退出, 你会发现终端输出了一些错误信息. 请分析这个错误信息是什么原因造成的, 然后尝试在NEMU中修复它.
使用 q 退出后,程序返回值为 1 而不是 0,进入 src/utils/state.c,可以看到 is_exit_status_bad 函数会根据 nemu_state 生成对应的返回值。
而调用 q 命令时并没有设置 nemu_state.state 的值,所以程序退出时返回值为 1。
因此我们只需要在调用 q 命令时设置 nemu_state.state 为 NEMU_QUIT 即可。
1.4 基础设施
Q.1 如何测试字符串处理函数?
你可能会抑制不住编码的冲动: 与其RTFM, 还不如自己写. 如果真是这样, 你可以考虑一下, 你会如何测试自己编写的字符串处理函数?
如果你愿意RTFM, 也不妨思考一下这个问题, 因为你会在PA2中遇到类似的问题.
不 RTFM:
- 功能正常测试;
- 边界测试(空指针、空字符串、缓冲区溢出、无截止符、重叠内存等);
RTFM: - 和标准库对拍自动测试。
1.5 表达式求值
Q.1 为什么printf()的输出要换行?
如果不换行, 可能会发生什么? 你可以在代码中尝试一下, 并思考原因, 然后STFW对比你的想法.
#include <stdio.h>
int main(void) {
printf("Hello World");
while(1);
return 0;
}如果运行以上代码,可以发现并不会输出 Hello World,但是如果把 "Hello World" 改为 "Hello World\n" 则会输出,这是 stdio 中的缓冲机制所造成的。stdio 的缓冲机制有三种:
- 行缓冲(Line Buffering)
- 默认情况下,面向终端(如
stdout)的文件流使用行缓冲。 - 缓冲区在以下情况被刷新:
- 输出了一个换行符
\n; - 缓冲区被填满;
- 主动调用刷新函数(如
fflush(stdout)); - 程序正常结束,流被关闭(如
exit()或return)。
- 输出了一个换行符
- 默认情况下,面向终端(如
- 全缓冲(Full Buffering)
- 默认情况下,面向文件的文件流(如
FILE*、管道)使用全缓冲。 - 缓冲区在以下情况被刷新:
- 缓冲区被填满;
- 主动调用刷新函数(如
fflush(file_stream)); - 程序正常结束,流被关闭(如
fclose()或exit())。
- 默认情况下,面向文件的文件流(如
- 无缓冲(Unbuffered)
- 默认情况下,标准错误流(
stdout)是无缓冲的。 - 缓冲区在每次 I/O 操作都会刷新。
- 默认情况下,标准错误流(
可以通过 setvbuf 或 setbuf 函数设置一个流的缓冲模式。
Q.2 实现带有负数的算术表达式的求值 (选做)
在上述实现中, 我们并没有考虑负数的问题, 例如
"1 + -1" "--1" /* 我们不实现自减运算, 这里应该解释成 -(-1) = 1 */它们会被判定为不合法的表达式. 为了实现负数的功能, 你需要考虑两个问题:
- 负号和减号都是
-, 如何区分它们?- 负号是个单目运算符, 分裂的时候需要注意什么?
你可以选择不实现负数的功能, 但你很快就要面临类似的问题了.
可以通过判断 - 左侧是否为表达式来区分,如果是表达式则作为减号,如果不是表达式则作负号。
在本人的实现中编写了一个 is_unitary 函数来判断在 pos 位置的重载操作符是否为其一元形式(如 - 号是否是负号含义,* 号是否为解引用的含义):
#define _KINDOF_1(op, a) ((op) == (a))
#define _KINDOF_2(op, a, b) ((op) == (a) || _KINDOF_1(op, b))
#define _KINDOF_3(op, a, b, c) ((op) == (a) || _KINDOF_2(op, b, c))
#define _KINDOF_4(op, a, b, c, d) ((op) == (a) || _KINDOF_3(op, b, c, d))
#define _KINDOF_5(op, a, b, c, d, e) ((op) == (a) || _KINDOF_4(op, b, c, d, e))
#define _KINDOF_6(op, a, b, c, d, e, f) ((op) == (a) || _KINDOF_5(op, b, c, d, e, f))
#define _GET_MACRO(_1, _2, _3, _4, _5, _6, _7, NAME, ...) NAME
#define KINDOF(op, ...) \
_GET_MACRO(op, ##__VA_ARGS__, _KINDOF_6, _KINDOF_5, _KINDOF_4, _KINDOF_3, _KINDOF_2, _KINDOF_1)(op, ##__VA_ARGS__)
bool is_unitary(size_t pos) {
// To determine whether an overloaded operand is in its unitary or binary form, e.g. * and -.
return pos == 0 || !KINDOF(tokens[pos - 1].type, TK_DEC, TK_HEX, /*TK_REG, TK_VAR, */')');
}在读取完所有 Token 之后,调用 process_oprand 来明确所有重载运算符的实际含义。
分裂时注意结合性,对于负号这种右结合的单目运算符,计算时不存在 lval ,只对 rval 进行计算。
同时由于最左侧的运算符最后被运算,此时主运算符应该是同优先级下最左侧的,比如 --1 被解释为 -(-1),主运算符应该是左边的负号(不然在一些实现下可能导致少算几个负号)。
Q.3 表达式生成器如何获得C程序的打印结果?
代码中这部分的内容没有任何注释, 聪明的你也许马上就反应过来: 竟然是个RTFM的圈套! 阅读手册了解API的具体行为可是程序员的基本功. 如果觉得去年一整年的程序员都白当了, 就从现在开始好好锻炼吧.
可以看到 gen_expr.c 中使用了 popen 函数来运行编译后的 C 程序。
fp = popen("/tmp/.expr", "r");
assert(fp != NULL);
int result;
ret = fscanf(fp, "%d", &result);
pclose(fp);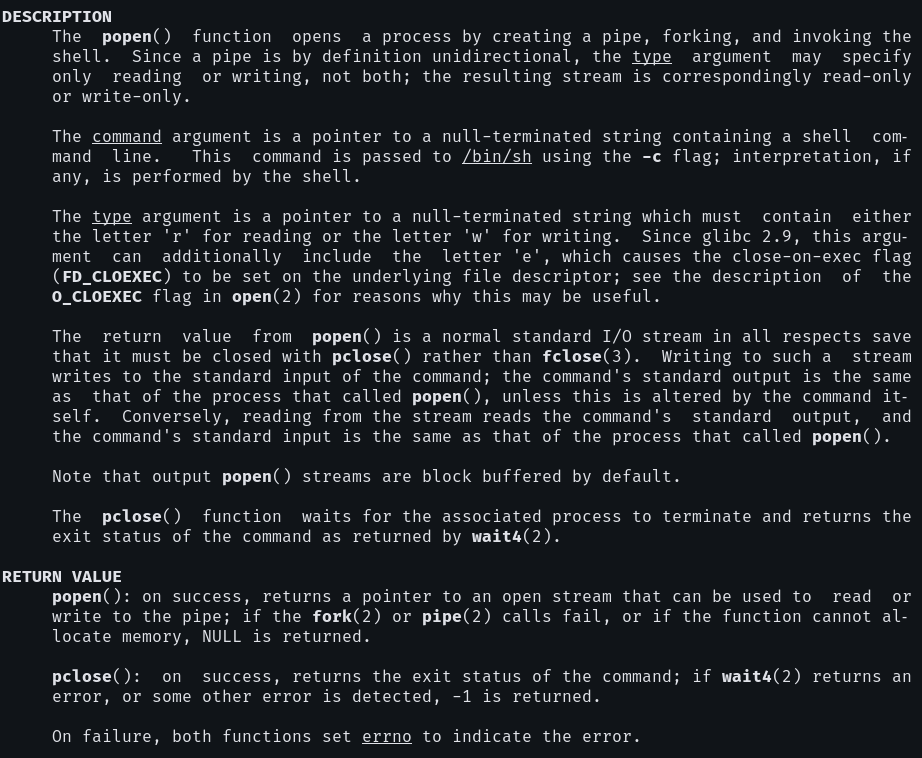
- 可以看到
popen()底层上是调用了/bin/sh -c来执行的,因此可以在command参数中使用管道符等 Shell 特性; - 由于标准管道是单向的,因此
popen()只支持只读/只写模式,也就是要么从程序的stdout读取输出,要么向程序的stdin写入数据,一般上不支持同时读写。 popen()的返回值是一个标准 I/O 流,但必须调用pclose()而不是fclose()来关闭这个流。
获取到 stdout 之后就可以调用 fscanf() 来格式化读取输出了。
Q.4 为什么要使用无符号类型?(建议二周目思考)
我们在表达式求值中约定, 所有运算都是无符号运算. 你知道为什么要这样约定吗? 如果进行有符号运算, 有可能会发生什么问题?
有符号类型的溢出计算是未定义行为(UB),在不同架构、不同编译器下可能对相同运算得到的结果不同。
Q.5 除 0 的确切行为
如果生成的表达式有除0行为, 你编写的表达式生成器的行为又会怎么样呢?
在编译时加入 -Werror=div-by-zero 让编译不通过,过滤掉除 0 的表达式。
注意不能依赖运行时爆 Floating Point Exception 来判断表达式是否存在除 0 的行为,因为编译器很有可能在编译时就对静态表达式进行了求值运算优化,但优化时不符合实际的情况(具体来说,在这个过程中除 0 的表达式的值将会是 0,但我们想让它 raise error)。
综上所述,最好的办法是在编译期中过滤除零的行为。
1.6 监视点
Q.1 温故而知新
框架代码中定义
wp_pool等变量的时候使用了关键字static,static在此处的含义是什么? 为什么要在此处使用它?
static 关键字可用于限制函数或变量的作用域,使变量可见性限制在当前文件内部。
在这些变量中使用 static 关键字可以起到封装的作用,只对外部暴露必要的 API。
Q.2 你会如何测试你的监视点实现?
我们没有提供监视点相关的测试, 思考一下, 你会如何测试?
当然, 对于实验来说, 将来边用边测也是一种说得过去的方法, 就看你对自己代码的信心了.
首先测试监视点的增删查功能,确保基础功能正常。
然后简单测试一下监视点的功能,测试边界条件。
Q.3 强大的GDB
如果你遇到了段错误, 你很可能会想知道究竟是哪一行代码触发了段错误. 尝试编写一个触发段错误的程序, 然后在GDB中运行它. 你发现GDB能为你提供哪些有用的信息吗?
#include <stdio.h>
int main() {
int *i = NULL;
*i = 100;
return 0;
}使用 gcc -g a.c -o a.out 来编译,gdb a.out 来调试,
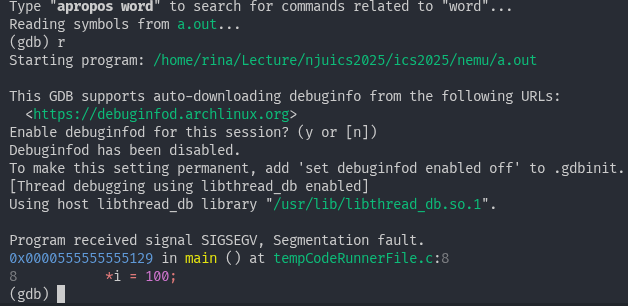
可以看到 gdb 输出了发生段错误所在的代码段行,可以进一步通过其他命令来获取相关信息(变量值/调用栈等等)。
Q.4 如何提高断点的效率 (建议二周目思考)
如果你在运行稍大一些的程序(如microbench)的时候使用断点, 你会发现设置断点之后会明显地降低NEMU执行程序的效率. 思考一下这是为什么? 有什么方法解决这个问题吗?
当前方案是在执行每一步指令后对监视点的 expr 进行计算,在每个 expr() 过程中可能会额外运行几千甚至几万条的指令,大大降低了执行速度。
对于断点类的监视点,我们可以借鉴软中断的思想。在断点对应的地址替换为软中断指令,当模拟器每次执行到这个指令时就代表断点被触发了,这样就省去了 expr() 过程带来的额外性能开销。
其他的优化方法还包括对断点类型进行特判(将断点和其他监视点区分开来,独立判断,也绕过了 expr() 过程)。
Q.5 一点也不能长?
x86的
int3指令不带任何操作数, 操作码为1个字节, 因此指令的长度是1个字节. 这是必须的吗? 假设有一种x86体系结构的变种my-x86, 除了int3指令的长度变成了2个字节之外, 其余指令和x86相同. 在my-x86中, 上述文章中的断点机制还可以正常工作吗? 为什么?
是必须的。
因为 x86 指令的最小长度为一个字节,如果 int 3 指令占两个字节,则可能导致在对一个字节的指令下断点时将后面的指令的一部分覆盖掉,导致后续执行错误。
综上所述,在 my-x86 中的断点机制在对单字节指令下断点时可能会出现问题。
Q.6 随心所欲的断点
如果把断点设置在指令的非首字节(中间或末尾), 会发生什么? 你可以在GDB中尝试一下, 然后思考并解释其中的缘由.
程序会执行错误,断点不会被触发。
x86 的断点实际上是利用了软中断,替换某个地址的值为 0xcc,而如果该位置为指令的非首字节,则会被当作指令的操作数来处理。所以执行程序时会出现错误,int 3 也不会被当作指令来处理所以不会造成中断。
Q.7 NEMU的前世今生
你已经对NEMU的工作方式有所了解了. 事实上在NEMU诞生之前, NEMU曾经有一段时间并不叫NEMU, 而是叫NDB(NJU Debugger), 后来由于某种原因才改名为NEMU. 如果你想知道这一段史前的秘密, 你首先需要了解这样一个问题: 模拟器(Emulator)和调试器(Debugger)有什么不同? 更具体地, 和NEMU相比, GDB到底是如何调试程序的?
模拟器是通过用代码模拟 CPU 来执行程序的,因此 CPU 及内存所有的状态均可以在模拟器代码中可控。而调试器是用真实 CPU 来调试运行程序的,所以要通过系统内核提供的系统调用来获取相关的状态。
简单来说,GDB 是通过 Linux 内核提供的 ptrace 来调试程序的。